

با داده های گمشده در پایتون چه کنیم؟

پیش پردازش داده ها یکی از مراحل مهمی است که معمولاً بیش از 80 درصد زمان تحلیلگران و دانشمندان علم داده را به خود اختصاص می دهد. یکی از مراحل پیش پردازش، کار با داده های گمشده یا همان missing data است. فرض کنید مدیر یک فروشگاه بزرگ هستید و می خواهید داده های مشتریان تان را جمع آوری کنید. به کمک ابزارهای حسابداری یا حتی اکسل، اطلاعات مشتریان تان را می گیرید و ذخیره می کنید. با اینحال برخی از مشتریان ممکن است اطلاعات درستی ارائه نکنند یا اصلاً تمایلی به ارائه اطلاعات به فروشگاه شما را نداشته باشند. در این شرایط دیتاستی که جمع آوری کرده اید حاوی داده های گمشده یا حتی اشتباهی خواهد بود که باید قبل از ساخت مدل پیش پردازش شود. حتماً از خودتان می پرسید چرا کار با داده های گمشده و مدیریت آن ها اینقدر اهمیت دارد؟ پاسخ به این سوال ساده است. بیشتر مدل های یادگیری ماشین قادر به مدیریت داده های نال نیستند و نمی توانند از پسِ آن ها به درستی بر بیایند. علاوه بر این، یک داده اشتباه می تواند نتیجه مدل را به کلی خراب کند و تصمیمات شما را تحت تاثیر خود قرار دهد. برای مدیریت چنین داده هایی روش های مختلفی وجود دارد که در این مقاله به طور مفصل درباره آن صحبت خواهم کرد.
چگونه داده های گمشده را مدیریت کنیم؟
همانطور که قبلاً نیز بیان کردم روش های مختلفی برای مدیریت این داده ها وجود دارد. در این مقاله می خواهم از دیتاست معروف تایتانیک برای بررسی داده های گمشده استفاده کنم. شما می توانید این فایل را از سایت کگل دانلود کنید.
حالا وقت دست به کد شدن است!
قبل از هر چیز باید کتابخانه هایی که برای این پروژه نیاز داریم را ایمپورت کنیم. کتابخانه هایی مثل پانداس، نامپای و matplotlib پای ثابت بیشتر پروژه های ما هستند. پس این کتابخانه ها را وارد محیط ژوپیتر نوت بوک می کنیم.
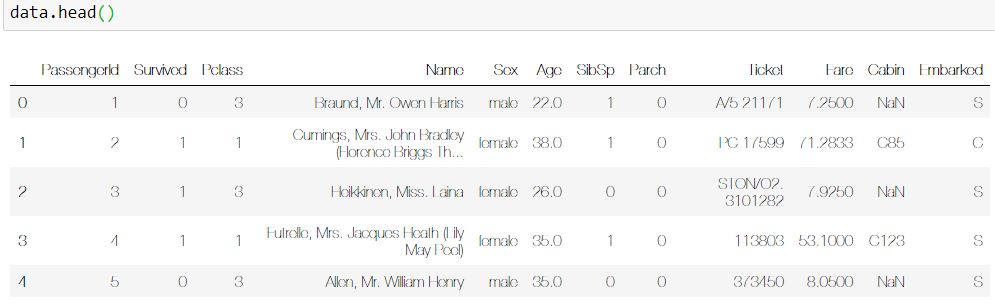
همانطور که در شکل بالا می بینید این دیتاست در خود ستون های مختلفی دارد. PassengerId, Name, Age تنها چند مورد از ستون های ما هستند. هدف ما از اجرای این پروژه یادگیری مدیریت داده های گمشده است. پس اولین سوالی که باید در این شرایط به آن پاسخ بدهیم این است: از کجا بفهمم دیتاست من missing data دارد؟
بررسی وجود داده های گمشده:
برای اینکه بفهمیم دیتاست مان داده گمشده دارد یا خیر چندین روش پیش رویمان داریم. شاید ساده ترین و مهم ترین روشی که به ما کمک می کند دید جامعی نسبت به دیتاست خود داشته باشیم استفاده از تابع info است. به شکل زیر خوب نگاه کنید. ما داده هایمان را در متغیری به اسم data ذخیره کردیم. حالا می توانیم به کمک کد data.info() اطلاعات بسیار خوبی درباره داده هایمان کسب کنیم. یکی از همین اطلاعات، وجود داده های نال یا گمشده است.
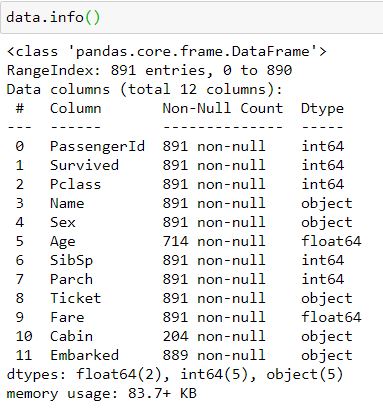
همانطور که در شکل می بینید سه ستون age، cabin و Embarked حاوی داده های گمشده هستند که باید مدیریت شوند. روش دیگری هم برای پیدا کردن missing data وجود دارد. به کمک کد data. isnull().sum() هم می توانید مجموع داده های نال در هر ستون را ببینید. بیایید نتیجه یا خروجی این کد را هم بررسی کنیم.
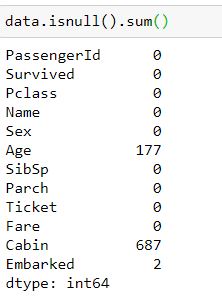
ستون age یکی از ستون هایی است که 177 داده گمشده در خود دارد. ستون کابین 687 داده نال و ستون embarked دو داده گمشده دارد. اگر یکی از الگوریتم های یادگیری ماشین مثل logistic regression یا SVM را روی این دیتاست اعمال کنید به طور حتم با خطا مواجه خواهید شد. چون این الگوریتم ها قادر به مدیریت داده های نال نیستند.
روش های مدیریت داده های گمشده:
حالا که درک کلی از دیتاست تایتانیک به دست آوردیم و متوجه شدیم سه ستون مان حاوی دیتاهای گمشده هستند می توانیم به سراغ روش هایی برویم که ما را از شر این داده ها خلاص می کنند. من برای راحتی کار ستون age را بررسی می کنم و یک به یک روش های برخورد با داده های گمشده را برایتان توضیح می دهم.
ستون هایی که داده گمشده دارند را پاک کنید:
در برخی از شرایط ستون ما داده های گمشده زیادی دارد. به عنوان مثال ممکن است از 1000 نمونه موجود 900 داده نال وجود داشته باشد. در این شرایط شاید عاقلانه ترین کار این باشد که ستون مدنظر را حذف کنیم. البته قانون ثابتی برای این موضوع وجود ندارد و شما باید بر اساس پروژه تان تصمیم بگیرید. من اینجا همه سناریوها را بررسی می کنم. ستون سن در این دیتاست 177 داده گمشده دارد. پس اگر من بخواهم کل این ستون را حذف کنم باید از کدی شبیه کد زیر استفاده کنم:
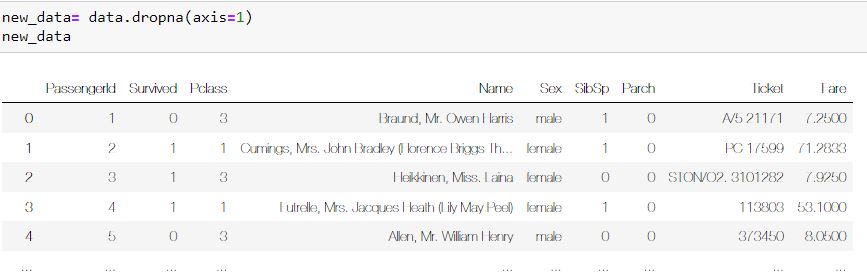
به کمک این کد همه ستون هایی که در خود داده نال یا گمشده دارند را حذف کردیم. حالا اگر از تابع info استفاده کنید متوجه می شوید که دیگر خبری از ستون سن در دیتاست مان نیست.
سطری که داده گمشده دارد را پاک کنید:
گاهی از اوقات استفاده از سناریوی بالا دیتاست ما را خراب می کند و داده های ارزشمند زیادی را نابود می سازد. اگر احساس کردید که به داده هایتان نیاز دارید و نمی توانید کل ستون را به یکباره حذف کنید می توانید سطری که در خود داده گمشده دارد را پاک کنید. بیایید این موضوع را به کمک کد زیر بررسی کنیم:
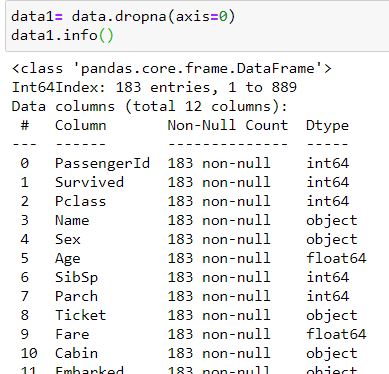
زمانی که از عبارت axis=0 استفاده می کنیم سطرهایی که در خود داده گمشده دارند را پاک می کنیم. هر چند این روش هم می تواند داده های ارزشمند زیادی را از ما بگیرد اما در برخی از سناریوها کارساز خواهد بود.
داده های گمشده را پر کنید:
تا به اینجای کار دو روش را با هم بررسی کردیم. همانطور که قبلاً هم گفتم دو روش بالا داده های ارزشمند زیادی را از بین می برند. خوب برای جلوگیری از این مشکل چه باید بکنیم؟ معلوم است! داده های گمشده را با اطلاعات خاصی پر می کنیم. تابع fillna به ما کمک می کند به شیوه های مختلف جای داده های گمشده را با مواردی که دوست داریم پر کنیم.
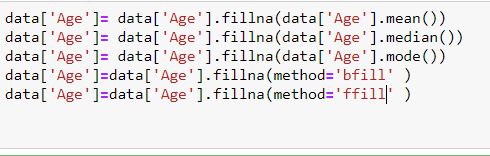
- شما می توانید missing data را با میانگین، میانه یا مد آن ستون پر کنید.
- می توانید داده های گمشده را با یک عدد ثابت پر کنید.
- می توانید داده های گمشده را با داده قبل یا بعد آن پر کنید.
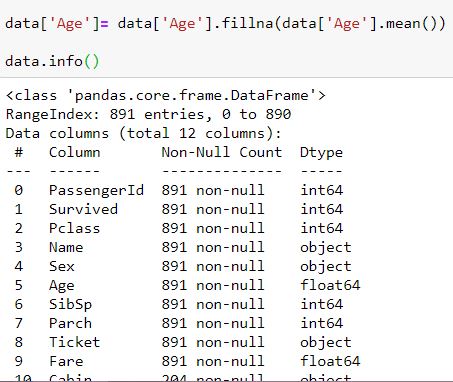
همانطور که در شکل می بینید من روش های مختلف پر کردن داده های گمشده را اجرا کرده ام. اگر دوست داشتید می توانید در تابع fillna و به کمک گزینه method روش پر کردن داده ها را به صورت backward fill یا forward fill قرار دهید.
حرف آخر:
در این مقاله سعی کردم روش های مختلفی که برای مدیریت داده های گمشده وجود دارد را بیان کنم. به طور حتم انتخاب شیوه مناسب به پروژه و دیتاست شما بستگی خواهد داشت. هیچ کدام از روش های بالا نسبت به دیگری برتری ندارند و در سناریوهای مختلف می توانند کارساز و مفید باشند. شما هم تجربه ای در این زمینه داشته اید؟ داده های گمشده را چگونه مدیریت کرده اید؟
دیدگاهتان را بنویسید