

پیش بینی رضایت مشتریان با الگوریتمهای یادگیری ماشین: بخش دوم
در بخش اول مقاله از روشهای مختلف بصری سازی استفاده کردیم تا دادههایمان را به تصویر بکشیم و ایده یا بینشهای مختلفی از آن بگیریم. حالا که تا حدودی درک درستی از دیتاستمان داریم میتوانیم به سراغ مدلسازی دیتاها برویم و از الگوریتمهای یادگیری ماشین برای پیش بینی رضایت مشتریان استفاده کنیم. در این مقاله به بررسی الگوریتمهای مختلف ماشین لرنینگ خواهیم پرداخت و به کمک این الگوریتمها مدلسازی خواهیم کرد. پس همراه من باشید.
بررسی دادههای پرت
اگرچه ما در مقاله قبلی ایدههای جذابی با بصری سازی دادهها به دست آوردیم اما هنوز چند مرحله تا مدلسازی فاصله داریم. از جمله فرآیندهای مهمی که در بیشتر پروژههای یادگیری ماشین باید در نظر داشته باشید بررسی وجود دادههای پرت یا همان Outlier ها در دیتاستتان است. اینکه داده پرت چیست و چه میکند را بعداً به طور مفصل با هم بررسی میکنیم. فقط همین قدر بدانید که برخی از الگوریتمها به شدت به دادههای پرت حساساند و وجود داده پرت میتواند دقت شان را تحت تاثیر خود قرار دهد.
روشها و تکنیکهای زیادی برای بررسی دادههای پرت در دیتاست وجود دارد. یکی از همین تکنیکها استفاده از متد IQR است. این متد به کمک ترسیم باکس پلات و بررسی آن به ما کمک میکند دادههایی که به احتمال زیاد پرت هستند را شناسایی کنیم. به کد زیر نگاه کنید:
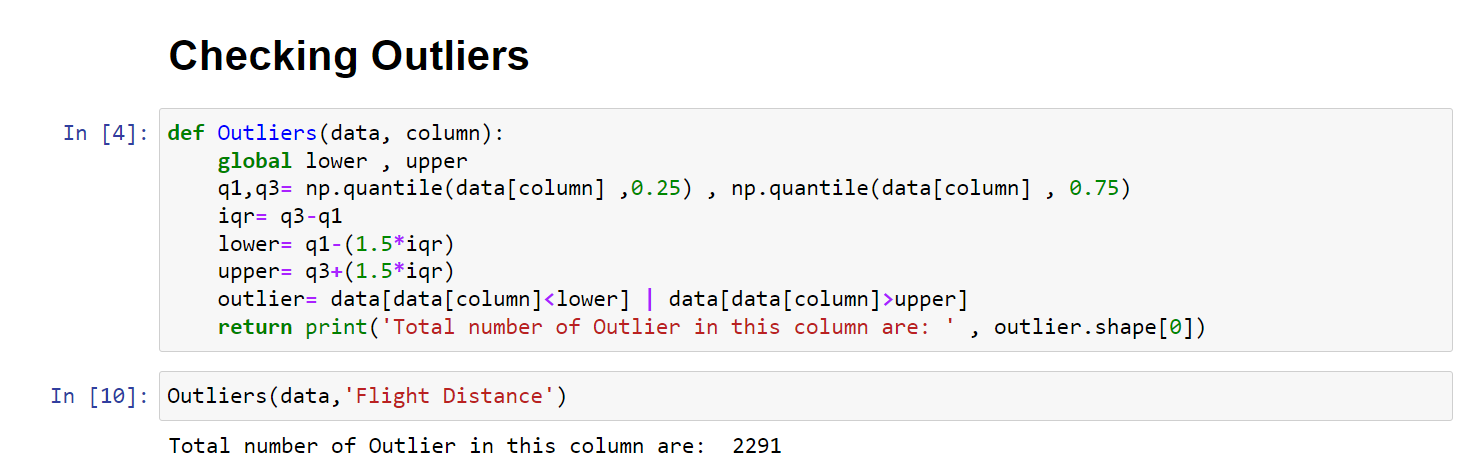
همانطور که میبینید در برخی از ستونهایمان داده پرت داریم. حالا با این دادههای پرت چه کنیم؟ شما میتوانید بسته به پروژه خود دادههای پرت را کاملاً حذف کنید یا اینکه آنها را نگه دارید. در بخش قبلی هم گفتم که برخی از الگوریتمها( به خصوص آنهایی که با بررسی و محاسبه فاصله درگیرند) ممکن است به دادههای پرت حساس باشند. پس اگر میخواهید از چنین الگوریتمهایی برای مدلسازی استفاده کنید حواس تان به outlier ها هم باشد. من به دادههای پرت دست نمیزنم.
تبدیل دادههای کیفی به کمی
اگر با الگوریتمهای ماشین لرنینگ آشنا باشید حتماً خیلی خوب میدانید که این الگوریتمها ارتباط خوبی با دادههای کیفی ندارند. پس قبل از مدلسازی باید چنین دادههایی را مدیریت کنیم. برای اینکار هم روشهای زیادی وجود دارد. استفاده از کتابخانه Sklearn یا استفاده از فانکشنهایی همچون lambda به ما کمک میکند دیتاهایی که کیفی هستند را به دیتای کمی تبدیل کنیم.

تقسیم دیتاست به تست و ترین
برای اینکه بتوانیم دیتاست خودمان را بررسی کنیم باید قبل از هر چیزی آن را به دیتاست تست و ترین تقسیم بندی کنیم. ابتدا الگوریتم را روی داده ترین آموزش میدهیم. بعد که الگوریتم همه چیز را یاد گرفت، دیتاست تست را به او میدهیم تا عملکردش را بسنجیم. ستون satisfaction یا همان رضایت مشتری ستون هدف ماست. فیچر تارگت، لیبل یا هدف همان چیزی است که میخواهیم با الگوریتمهای یادگیری ماشین پیش بینی کنیم.
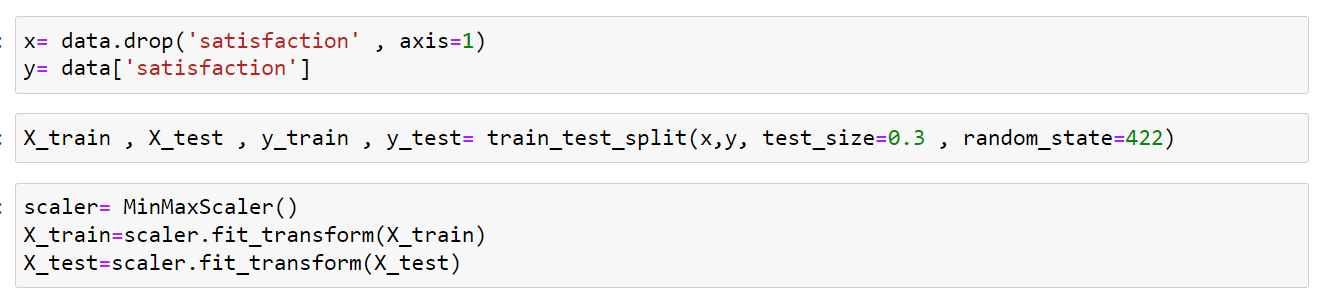
بعد از تقسیم دیتاست به دو بخش ترین و تست نوبت به استانداردسازی یا نرمالسازی دادهها میرسد. به دلیل جلوگیری از مشکلاتی همچون data leakage یا همان نشت دادهها توصیه میشود فرآیند نرمالسازی را روی دادههای تقسیم شده انجام دهید. از آنجایی که در دیتاست ما دادهها مقیاس مشابهی ندارند استفاده از این فرآیند باعث میشود از عملکرد مدلمان اطمینان بیشتری داشته باشیم.
ساخت مدل به کمک الگوریتمهای یادگیری ماشین
خوب بیش از 80 درصد مسیر را طی کردهایم. حالا نوبت به اجرای الگوریتم و مدلسازی بر روی دادههای ترین می رسد. شما گزینههای مختلفی پیش رو دارید. میتوانید از الگوریتمهای متعددی استفاده کنید، دقت هر کدام را بسنجید، آزمون و خطا کنید هایپرپارامترها را تغییر دهید و در نهایت از بین گزینههای موجود بهترینها را گلچین کنید. من از الگوریتمهای مختلفی مثل رندوم فارست، درخت تصمیم، آدابوست و غیره استفاده کردم. تصویر زیر دقت هر کدام از این مدلها را نشان میدهد.
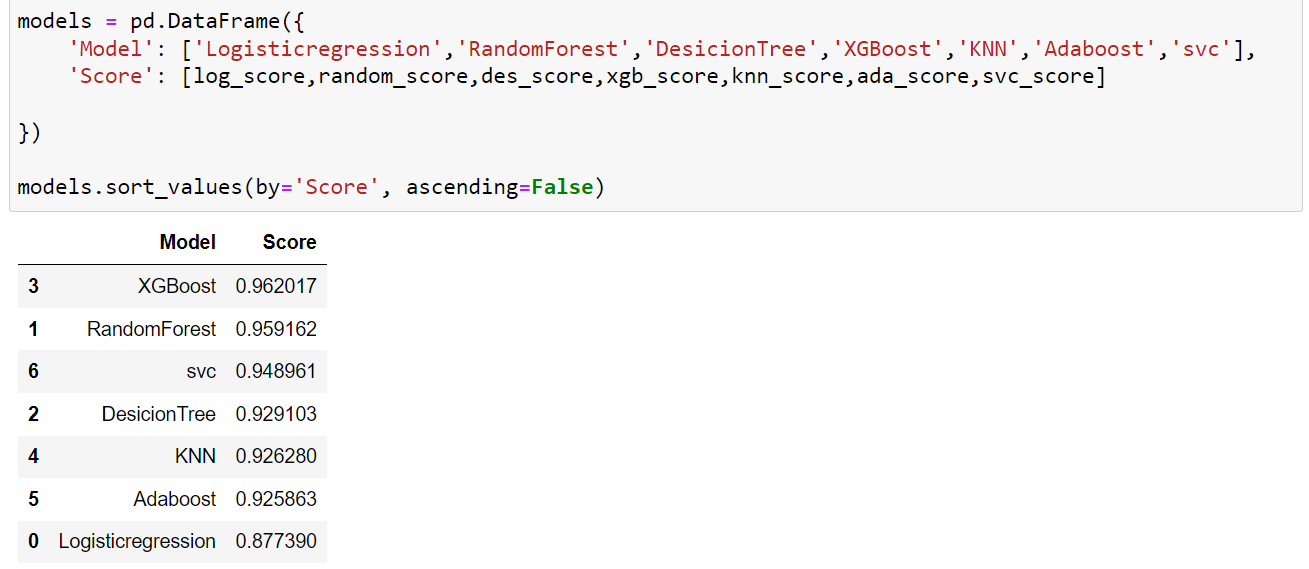
همانطور که می بینید دقت الگوریتم XGBoost بالاتر از سایر الگوریتمهاست. الگوریتم جنگل تصادفی هم دقت خوبی برایمان داشته است. حالا شما میتوانید هایپرپارامترها را تغییر دهید تا دقتتان را بررسی کنید و به نتایج بهتری دست پیدا کنید.
ستونها یا فیچرهای مهم
یکی از مسائل مهمی که به هنگام ساخت مدل باید به خاطر داشته باشید انتخاب ویژگی یا شناسایی ویژگیهای مهم است. فیچرهای مهم تاثیر بهتری بر روی پیش بینیهای ما دارند و کمکمان میکنند محاسبات کمتری را برای رسیدن به هدف انجام دهیم. تکنیکهای متنوعی برای انتخاب ویژگی وجود دارد اما این تکنیکها را میتوان در سه دسته مهم filter، wrapper و embedded قرار داد.
بررسی دیتاست نشان میدهد برخی از فیچرها همچون راحتی صندلی، سرگرمیهای طول پرواز، کلاس پرواز، نوع سفر و وجود وای فای در طول پرواز تاثیر بیشتری بر روی رضایتمندی مشتریان داشته است.
سخن نهایی
در دو مقاله اخیر سعی کردم کاربرد ماشین لرنینگ در کسب وکارهایی همچون صنعت هواپیمایی را بررسی کنم. حالا با پیشرفت علم شما میتوانید فاکتورهایی که باعث افزایش رضایت مشتریان تان میشوند را شناسایی کنید و در خدمات و محصولاتتان به کار ببرید. دیگر مجبور نیستید از حدس و گمان استفاده کنید. این تنها بخشی از کاربرد علم جذاب داده در دنیای کسب وکارهاست. در مقالات بعدی کاربردهای جذابتری را با هم بررسی خواهیم کرد.
دیدگاهتان را بنویسید