

مقدمه ای بر کتابخانه پانداس(pandas) در پایتون

پانداس یکی از کتابخانه های مهم و کاربردی پایتون به حساب می آید که کاربردهای بسیاری در دنیای علم داده دارد. این کتابخانه جزء کتابخانه های متن باز پایتون محسوب می شود و می تواند کارکردهای مختلفی برایتان داشته باشد. اگر بخواهید داده هایتان را وارد محیط کارتان کنید، آن ها را به اشکال مختلف بصری سازی کنید، تغییراتی روی داده ها انجام دهید یا دیتاست های مختلف را با هم ادغام کنید به قدرت پانداس نیاز خواهید داشت. در این مقاله سعی می کنیم به طور مختصر با پانداس و کاربردهای آن آشنا شویم و در مقالات بعدی به سراغ آموزش مباحث پیچیده تر و البته جذاب تر برویم.
چرا از پانداس استفاده می کنیم؟
قبل از اینکه به سراغ مباحث مهم تر برویم باید سنگ هایمان را با خود وا بکنیم. اولین و مهم ترین سوالی که به ذهن مان خطور می کند این است. چرا باید از pandas استفاده کنیم؟ مگر با اکسل نمی شود روی داده ها کار کرد؟ کار بر روی داده ها و ایجاد تغییرات بر روی آن ها کار ساده ای نیست. اگرچه اکسل کاربردهای مهمی در این زمینه دارد و قابلیت های بی نظیری در اختیارتان قرار می دهد اما عملکرد خوبی بر روی دیتاست های بزرگ ندارد. در ادامه با چندین مثال متوجه خواهید شد که استفاده از پانداس ساده تر و سریع تر از اکسل است و مسیر تحلیل داده را برایتان تسهیل می کند. حالا بیایید فهرست وار کاربردها و مزایای پانداس را بررسی کنیم.
- مدیریت داده ها به کمک پانداس به راحتی انجام می شود:
اولین و مهم ترین مزیتی که استفاده از کتابخانه پانداس برایمان به ارمغان می آورد مدیریت داده هاست. در سری آموزش های بعدی خواهیم دید که این کتابخانه ساختار داده ای بی نظیری دارد و به شما اجازه می دهد از سری ها و دیتافریم ها برای مدیریت داده هایتان استفاده کنید. به کمک این موارد قادر خواهید بود داده هایتان را موثرتر به نمایش بگذارید و آن ها را به شیوه های مختلف دستکاری کنید. همین ویژگی پانداس را به یک کتابخانه منحصر به فرد و کاربردی تبدیل می کند.
- مدیریت داده های گمشده یا ناموجود(missing data) در پانداس ساده تر است:
تا به حال برایتان پیش آمده است که یک دیتاست را برای تجزیه و تحلیل مورد بررسی قرار دهید و متوجه شوید برخی از ستون های آن مقادیر نال یا خالی دارند؟ همانطور که می دانید دیتا یک موضوع پیچیده است و اگر به درستی پردازش نشود کار بر روی آن سخت خواهد بود. یکی از مشکلاتی که دیتاساینتیست ها و تحلیلگران علم داده با آن دست و پنجه نرم می کنند داده های گمشده یا ناموجود است. کتابخانه پانداس برای این مشکل هم راه حل های مختلفی دارد. به عنوان مثال شما می توانید داده های نال را با میانگین یا میانه آن ستون پر کنید، ستون خاصی را که در آن داده های نال وجود دارد حذف کنید یا سطری که در آن داده خالی وجود دارد را از دیتاست تان حذف نمایید. تمامی این قابلیت ها به شما کمک می کنند دیتاست تمیزی داشته باشید و کار مدل سازی را راحت تر انجام دهید.
- ورودی و خروجی گرفتن از داده ها مثل آب خوردن خواهد بود:
شاید فکر کنید دارم اغراق می کنم اما اینطور نیست. پانداس قابلیت های مختلفی در اختیارتان قرار می دهد که خواندن داده ها از منابع مختلف را ساده تر می کند. همه ما خیلی خوب می دانیم که داده ها از منابع مختلفی در اختیار تحلیلگران داده قرار می گیرد و خواندن آن ها از اهمیت بسیار زیادی برخوردار است.
- تمیز کردن داده ها به کمک پانداس ساده تر از آن چیزی است که فکرش را می کنید:
اگر از دانشمندان علم داده سوال کنید به شما می گویند که مدل سازی بر روی داده ها تنها 2 یا 3 درصد فرآیند داده کاوی را به خود اختصاص می دهد. بیش از 98 درصد زمان شما صرف تمیز کردن داده ها و تحلیل مشکلات کسب وکارها خواهد شد. حالا اگر ابزار مناسبی برای تمیز کردن داده ها در اختیار نداشته باشید بدون شک بعد از چند ماه از شغل تان خسته خواهید شد و سر به بیابان خواهید گذاشتJ . البته نیازی نیست نگران باشید. پانداس مثل یک قهرمان بی بدیل همه این کارها را به راحتی برایتان انجام می دهد. در قسمت های بعدی این آموزش خواهید دید که کتابخانه پانداس و قدرت آن با هیچ کدام از ابزارهایی که تا به حال دیده اید قابل مقایسه نیست.
- پانداس از فایل هایی با فرمت های مختلف پشتیبانی می کند:
همانطور که قبلاً هم گفتم وظیفه شما به عنوان دیتا آنالیست این است که داده ها را از منابع مختلف جمع آوری کنید و آن ها را وارد محیط ژوپیترنوت بوک یا سایر IDE ها نمایید. Pandas به شما کمک می کند فایل هایی با فرمت های مختلف را وارد محیط کاری تان کنید و آن ها را مورد بررسی قرار دهید. این کتابخانه از فرمت های مختلفی همچون JSON, CSV, HDF5 و اکسل پشتیبانی می کند. چه چیزی از این بهتر؟؟
- به کمک پانداس می توانید دیتاست های مختلف را با هم جوین کنید:
گاهی از اوقات برایتان پیش می آید که بخواهید دو دیتاست مختلف را با هم ادغام کنید و از اطلاعات آن ها در کنار هم بهره ببرید. اینجاست که پانداس وارد میدان می شود و کار را برایمان راحت تر می کند. به کمک فانکشن ها و متدهایی که در پانداس داریم می توانیم دیتاست ها را به شیوه های مختلف با هم ادغام کنیم.
- بصری سازی داده ها در پانداس هم به راحتی انجام می شود:
حتماً شما هم شنیده اید که می گویند یک تصویر بهتر از هزاران کلمه است. اگر بگویم بصری سازی یک کار جادویی در پایتون است و مسیر تحلیل داده را به بهترین شکل ممکن تسریع می کند اغراق نکرده ام. اگر بتوانید داده هایتان را به خوبی به تصویر بکشید و آن ها را به شکل تصویر بررسی کنید دید بهتری نسبت به آن ها خواهید داشت. اگرچه کتابخانه های مختلفی برای بصری سازی داده ها در پایتون وجود دارد اما به کمک پانداس هم می توانید این وظیفه خطیر را به راحتی انجام دهید.
نحوه نصب پانداس
شما می توانید از طریق CMD و با وارد کردن عبارت pip install pandas این کتابخانه را به راحتی نصب کنید. اگرچه روش های دیگری هم برای نصب پانداس وجود دارد اما این روش ساده و بی دردسر است.
بررسی قابلیت های پانداس با چند مثال ساده
به نظر من مطالعه تئوری وار مطالب کافی نیست. برای اینکه بتوانید بر روی کتابخانه های پایتون تسلط پیدا کنید باید آستین هایتان را بالا بزنید و دست به کد شوید. زمانی که یک دیتاست رو بررسی می کنید قبل از هر کاری باید چندین سوال مختلف از خودتان بپرسید تا مسیر تحلیل تان را به سمت و سویی ببرید که منافع زیادی برای کسب وکار مدنظر داشته باشد.
همانطور که قبلاً هم گفتم اولین کار شما به عنوان دیتا آنالیست و حتی دیتاساینتیست این است که داده ها را درک کنید، سوالات مختلفی درباره دیتاست از خودتان بپرسید و در فرآیند تجزیه و تحلیل تان به دنبال پاسخگویی به این سوالات باشید. فرض کنید در یک شرکت به عنوان تحلیلگر داده استخدام شده اید و قرار است داده های فروش آن را بررسی کنید. دیتاستی که تیم فروش یا بازاریابی جمع آوری کرده است را به شما می دهند و انتظار دارند بینش های جذابی از آن به دست بیاورید. بیایید نگاهی کوتاه به این دیتاست بیندازیم:
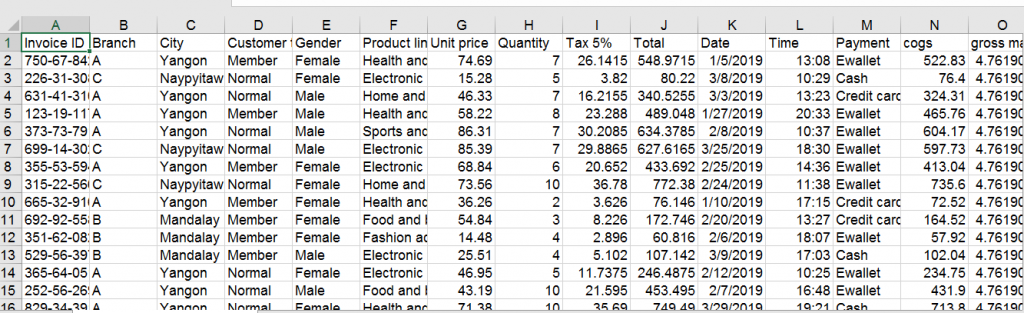
همانطور که می بینید دیتاست ما مربوط به فروش یک سری محصول است که تعداد فروش هر محصول بر اساس ماه و نوع فروشگاه را نشان می دهد. برای اینکه دیتاست تان را راحت تر تجزیه و تحلیل کنید سوالاتی که به ذهن تان می رسد را در یک دفترچه یادداشت یا فایل ورد بنویسید( بعد از اینکه حرفه ای شدید دیگر نیازی به اینکار نخواهید داشت). مثلاً می می خواهم سوالات زیر را بررسی کنم و پاسخ آن ها را به کمک پانداس به دست بیاورم.
- کدام محصول بیشترین مقدار از فروش را به خود اختصاص داده است؟
- مشتریان ما بیشتر خانم هستند یا آقا؟
- کدام نوع از مشتریان بیشترین خرید را داشته اند؟
بیایید پاسخ این سوالات را به صورت قدم به قدم بررسی کنیم.
گام اول: ایمپورت داده ها به کمک پانداس
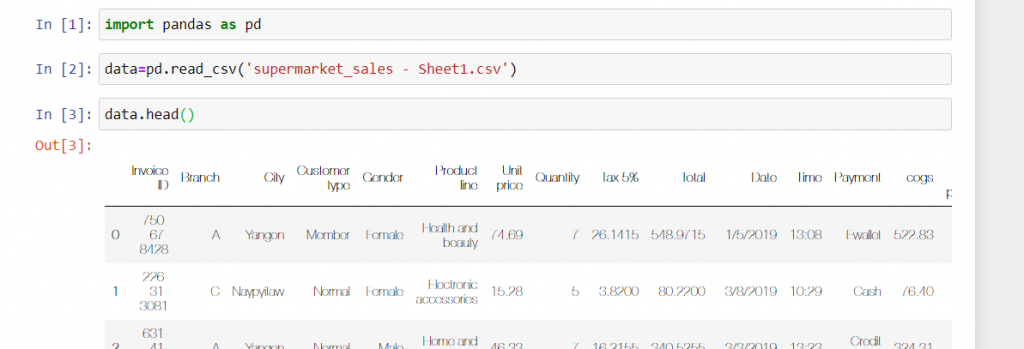
اگر پانداس را هنوز نصب نکرده اید بخش مربوط به نصب پانداس را خوب بخوانید و این کتابخانه را روی سیستم تان نصب کنید. حالا که پانداس روی سیستم مان نصب شده است وارد محیط ژوپیتر نوت بوک می شویم و یک فایل پایتون جدید می سازیم. اسم فایل را به tamrin تغییر می دهیم تا بعداً هم بتوانیم بر روی آن کار کنیم.
کتابخانه پانداس را به کمک کد زیر ایمپورت می کنیم.
Import pandas as pd
یک متغیر به اسم data می سازیم تا داده هایمان را در آن بریزیم.
Data= pd.read_excel(“esme file”)
داخل کوتیشن مارک باید مسیری که فایل تان را در آن ذخیره کرده اید بنویسید. در مقالات بعدی بیشتر راجع به این موضوع صحبت خواهیم کرد.
گام دوم: پاسخ به سوالات
حالا دیتاست ما وارد محیط کاری ژوپیتر شده است. پس می توانیم به سراغ سوالات مان برویم و یک به یک آن ها را جواب بدهیم.
سوال اول: کدام خط از محصول بیشترین مقدار از فروش را به خود اختصاص داده است؟
ستون Product line در این دیتاست اطلاعات ارزشمندی درباره خطوط مختلف محصولات به ما ارائه می دهد. برای اینکه این ستون و مقادیرش را بررسی کنیم چندین روش پیش رویمان داریم. به کمک تابع unique می توانیم مقادیر منحصر به فردی که در این ستون داریم را ببینیم. اگر دوست داشتید مقدار هر خط محصول را هم ببینید باید از تابع value_counts() استفاده کنید. تصاویر زیر همه چیز را به خوبی نشان می دهد:
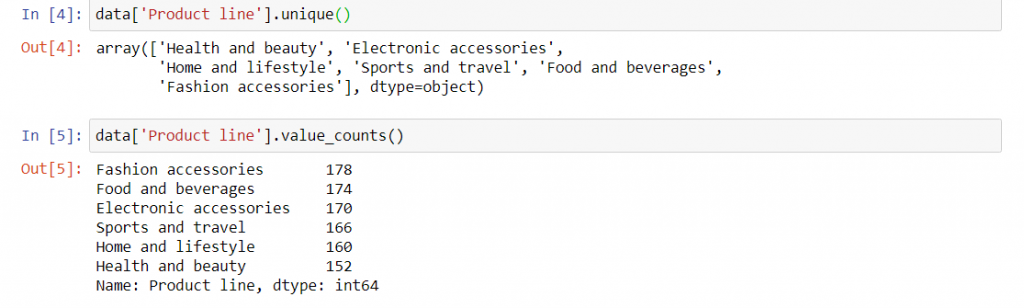
همانطور که از خروجی تابع unique می بینید ما شش خط محصول داریم که هر کدام بخشی از نیازهای مشتریان این فروشگاه را برآورده می کنند.
خروجی تابع value_counts هم نشان می دهد از هر خط محصول چه تعداد برای فروش داشته ایم. مثلا بخش سلامت و زیبایی تنها 152 مورد را به خود اختصاص داده است. این در حالیست که بخش اکسسوری های فشن 178 مورد را به خود اختصاص داده.
خوب حالا می دانیم که ما شش خط محصول داریم و از هر کدام چه تعداد در این دیتاست وجود دارد. به کمک یک تابع ساده مثل groupby می توانیم پاسخ سوال اول را پیدا کنیم.
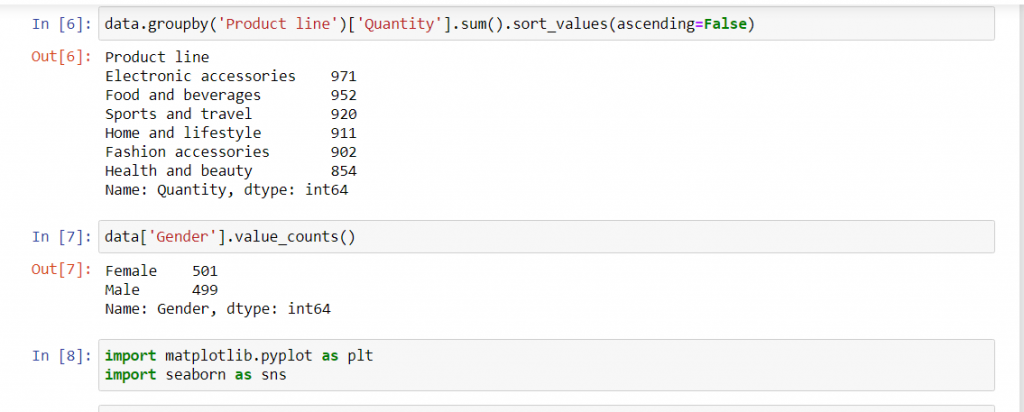
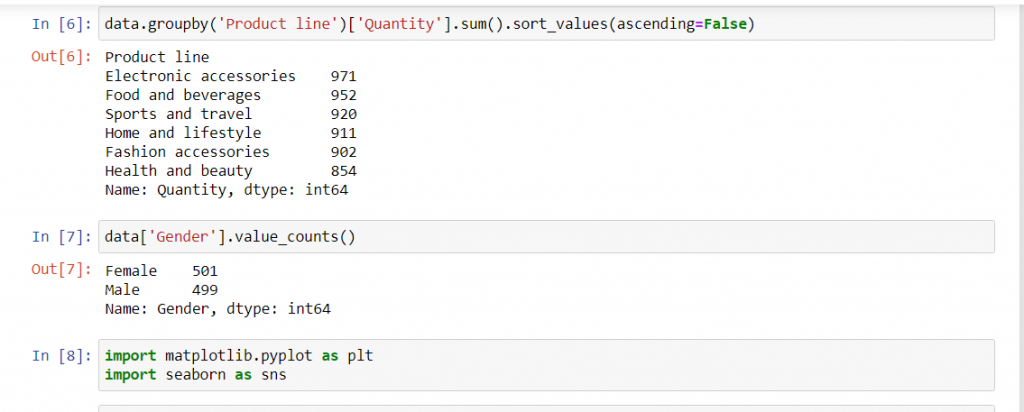
کد بالا به ما می گوید خط محصول اکسسوری های الکترونیک با 971 آیتم فروخته شده در صدر جدول فروش ما قرار دارد. هر چند فاصله بین فروش خطوط محصول زیاد نیست اما همین بررسی ساده به ما نشان می دهد بخش اکسسوری الکترونیک نسبت به بخش زیبایی و سلامت تعداد بیشتری فروش داشته است.
پاسخ سوال دوم: مشتریان ما بیشتر خانم هستند یا آقا؟
یکی از کارهای مهمی که بازاریابان انجام می دهند بخش بندی مخاطب ها بر اساس وضعیت جمعیت شناسی آن هاست. به عنوان مثال اینکه بدانیم مشتری های ما بیشتر خانم هستند یا آقا کمک مان می کند تبلیغات مناسب تری بسازیم، محتوای مرتبط تری تولید کنیم و محصولات مناسب تری را در انبارهایمان ذخیره کنیم. کد زیر به ما نشان می دهد چه تعداد مشتری آقا داریم و چند نفر از مشتری هایمان خانم هستند:
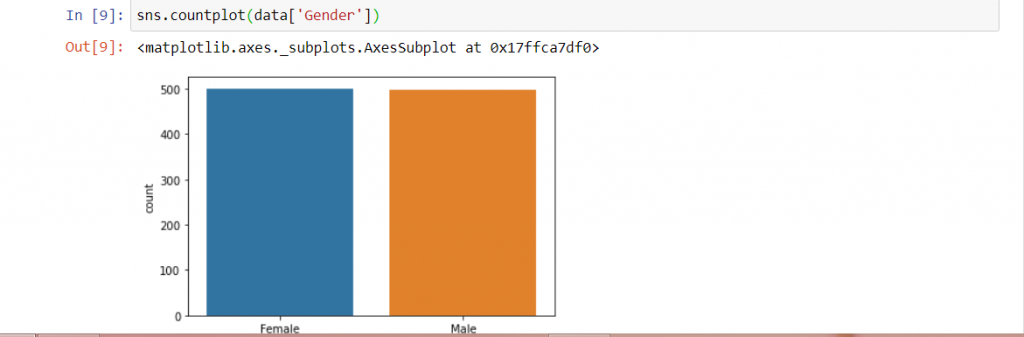
خروجی کد بالا هم خیلی جذاب است. 501 نفر از 1000 مشتری ما خانم هستند و 499 نفر از مشتری هایمان هم آقا. این موضوع نشان می دهد مشتری های این فروشگاه از لحاظ جنسیتی به شیوه یکسانی توزیع شده اند.
پاسخ سوال سوم: کدام نوع از مشتریان بیشترین خرید را داشته اند؟
در دیتاستی که داریم تجزیه و تحلیلش می کنیم ستونی به اسم Customer type وجود دارد. در صنعت خرده فروشی برای خدمات رسانی به مشتریان باشگاهی به اسم باشگاه مشتریان تشکیل می شود. اعضای این باشگاه ها معمولا خدمات و تخفیف های فوق العاده ای دریافت می کنند و می توانند به مشتری پر و پا قرص ما تبدیل شوند. به نظر می رسد این فروشگاه هم مشتری هایش را بر همین اساس طبقه بندی کرده است. برای اینکه حدس مان را بررسی کنیم به کمک unique یا value counts تعداد موارد منحصر به فردی که در این ستون هست را شناسایی می کنیم:
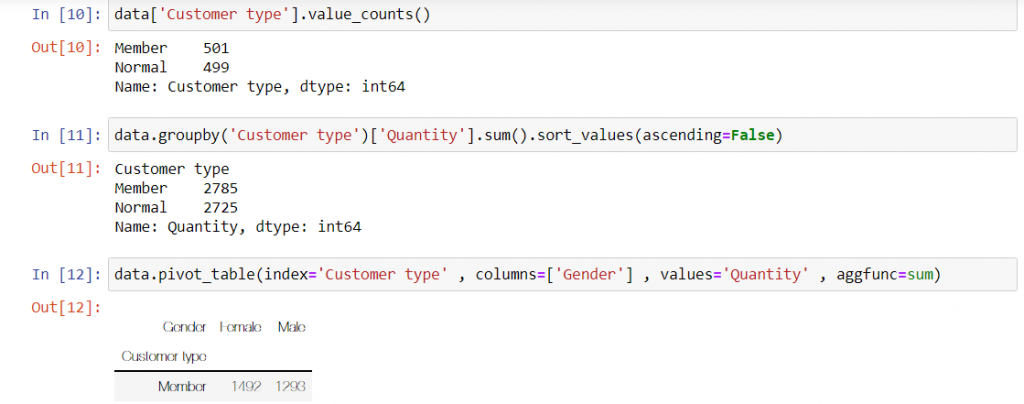
همانطور که می بینید ما دو عضو منحصر به فرد در این ستون داریم: یک مشتری معمولی(normal) و دیگری مشتری عضو(member). به نظر می رسد که حدس مان درست بوده است. حالا بیایید ببینیم کدام یک از این مشتری ها خرید بیشتری داشته اند:
مشتری هایی که عضو باشگاه بوده اند 2785 مورد از ما خرید کرده اند و مشتری هایی که عضو باشگاه نبوده اند2725 مورد. همین تجزیه و تحلیل ساده نشان می دهد مشتری هایی که عضو باشگاه ما بوده اند خرید بیشتری داشته اند.
سوال چهارم: از میان خانم ها و آقایان کدام یک بیشتر عضو باشگاه بوده اند و خرید بیشتری داشته اند؟
برای اینکه بتوانیم پاسخ بهتری به این سوال بدهیم باید از قابلیت pivot table استفاده کنیم. اگر با اکسل کار کرده باشید به طور حتم با pivot table ها آشنا هستید. این جداول به ما کمک می کنند دیتاست مان را بهتر و راحت تر تجزیه و تحلیل کنیم. به کدی که من نوشته ام نگاهی بیندازید:

خروجی این کد به ما می گوید خانم ها بیشتر از آقایان عضو باشگاه مشتریان مان بوده اند و در عین حال مقدار خرید بیشتری داشته اند.
حرف آخر:
پانداس یکی از کتابخانه های فوق العاده پایتون برای تحلیل داده است. در این مقاله سعی کردم با یک مثال ساده کاربرد این کتابخانه را نشان بدهم. هر چند این تحلیل عمیق نبود و نیاز به بررسی بیشتری داشت اما همین چند خط کد دید بهتری نسبت به فروشگاه به ما داد. به خاطر داشته باشید که در دیتاست های پیچیده و بزرگ استفاده از پانداس به جای ابزارهایی همچون اکسل کارتان را به مراتب راحت تر می کند.
دیدگاهتان را بنویسید